词向量总结

对于常见的词向量的总结
1 word embedding介绍
词嵌入是NLP任务中语言模型和特征学习的统称,用来将单词或者词组映射到实数域上的向量。
在NLP任务的底层输入中,使用词嵌入的方式将文本向量化,可以极大提高对应的NLP任务的效果。
简单说,就是找一种方法,把输入的文本进行向量化的表示。从而进行后续的任务。
2 发展历史
词向量的大致发展过程可以看成从统计学角度到语言模型的角度。
从机器学习再到深度学习。
2.1 统计模型:One-Hot 编码
构建字典/词表,基于字典/词表,对每一个单词进行编码。
构建步骤:
- 建立一个|V|(V表示词汇表总长度)的全零向量
- 将每个单词在词表中中对应的index维度置为1,其他元素保持为0
缺点:
- 词表维度过大(数万或者数十万级别),导致词向量稀疏,计算量大
- 单词与单词之间是独立的,无法体现单词之间的关系。任意两个词向量的内积均为0,与单词的实际意义不符。
2.2 统计模型:共现向量
每一个词不是相互独立的,与其相邻的单词关系密切。基于共现窗口,统计窗口内词语出现的频率,构建共现矩阵。
示例
以三句话为例,设定窗口为1,构建共现矩阵,并将单词编码
-
句子1:I like NLP
-
句子2:I like deep learning
-
句子3:I enjoy working
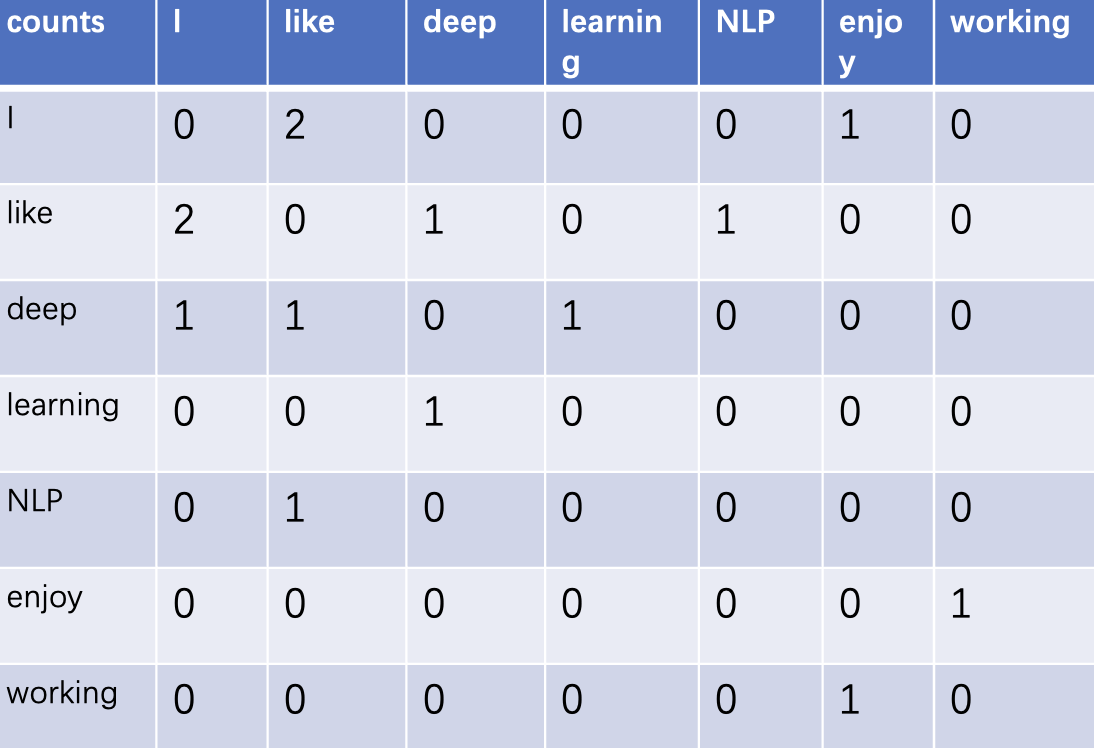
缺点:
-
每个词向量维度为|V|,导致计算量较大。
-
每当登陆新词时,需要统计更新整个共现矩阵 (V*V)。
-
仅考虑了词与词的共现关系,没有考虑对应的语义信息。
2.2 语言模型
语言模型,就是判断一段序列是不是一句话。机器学习中,有基于隐马尔科夫等理论的语言模型。
这里跳过,介绍一下深度学习的模型。由2003年的论文中首次提出,使用神经网络训练语言模型(NPLM)。
通过训练语言模型的任务,将训练完成后的embedding层作为对应的词向量。
模型介绍:
-
任务:给定当前词的上文(n-1个单词),预测当前词。
-
embedding层:使用one-hot将输入单词编码(1 * V),与词表(V * m)映射,将输入单词转换为维度为1*m的向量。n-1个单词拼接为(n-1)*m
-
隐藏层:通过线性变换+tanh激活函数。输出维度为1*h。
-
输出层:通过线性层将隐层输出转成1*V,并通过softmax计算各个单词的概率。取概率最大值对应的单词为模型输出。
-
损失函数:交叉熵
-
词向量:训练完成后,embedding层中V*m的词表即可作为词向量使用。
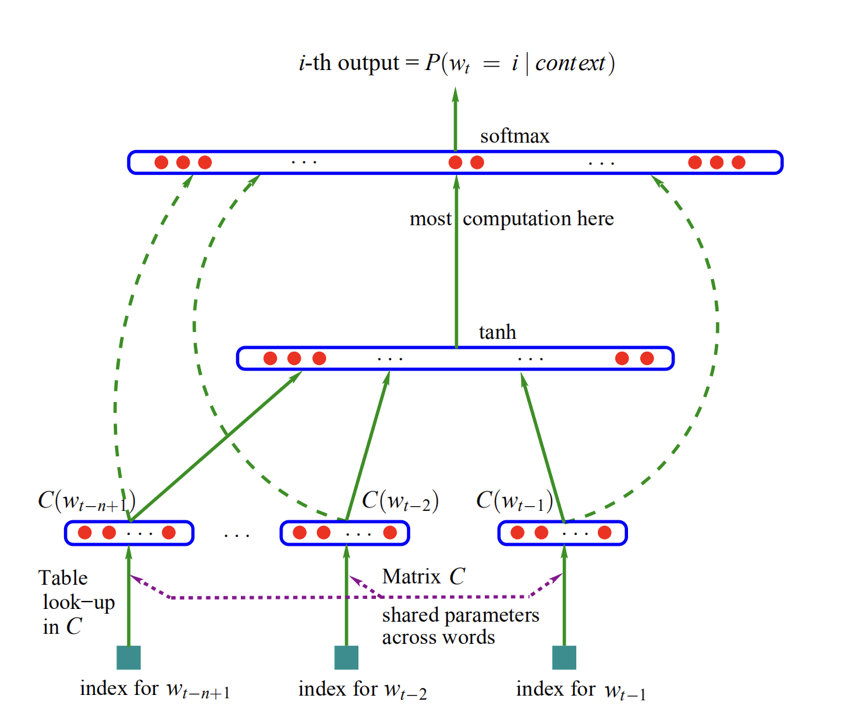
模型局限
- 训练与预测过程以词表的大小成线性关系,计算开销过大,耗时过久。后续word2vec模型基于此模型进行改进。
3 常见模型介绍
在bert火热之前,词向量的主要方法就是word2vec,也有一部分使用glove的方法。本节主要讲解两个算法的基本思路。
3.1 word2vec
3.1.1 基本结构
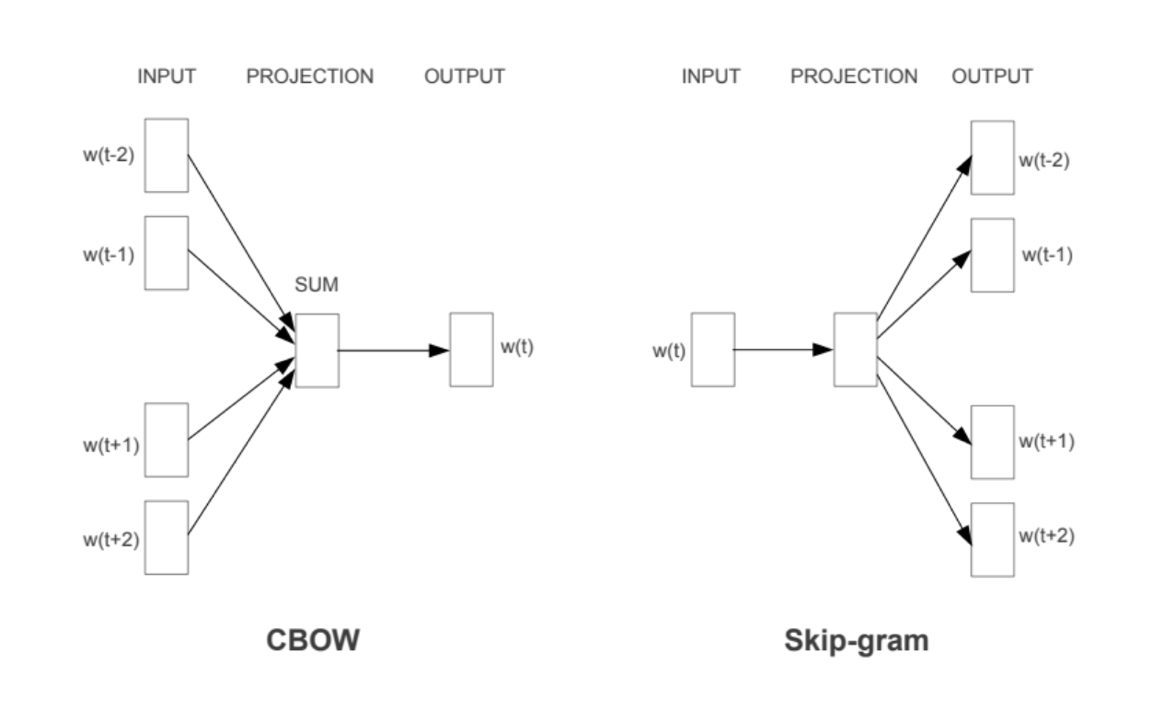
CBOW
-
任务:由上下文预测当前词
-
输入:当前词前后各n/2个词
-
输出:softmax后概率最大的词
Skip-Gram
-
任务:由当前词预测上下文
-
输入:当前单词
-
输出:softmax后概率前n大的单词
问题与改进
-
局限:每次softmax需要计算V个单词的概率,计算量极大,训练速度慢
-
改进:层次softmax和负采样
3.1.2 层次softmax
3.1.2.1 哈夫曼树
哈夫曼树建立过程
-
输入:含有权值的n个节点
-
步骤1:将输入看成有n棵树的森林,每棵树仅有一个节点
-
步骤2:在森林中选择权值最小的两棵树进行合并,得到新的树,新树的权重为左右子树根节点权重之和。
-
步骤3:将之前权值最小的两个数从森林删除,并将新的树加入森林。
-
步骤4:重复步骤2,3,直到森林中只有一棵树
-
输出:构建后的哈夫曼树
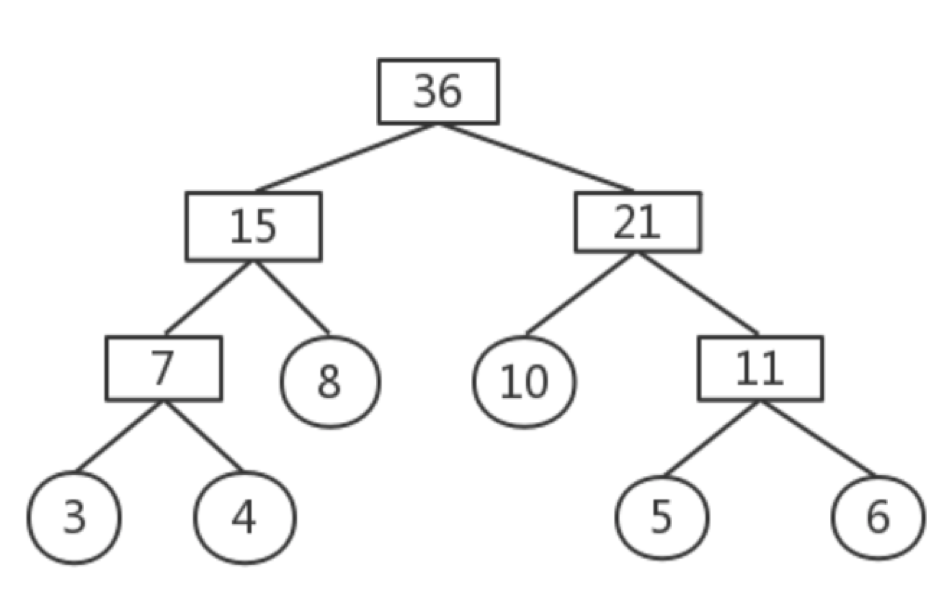
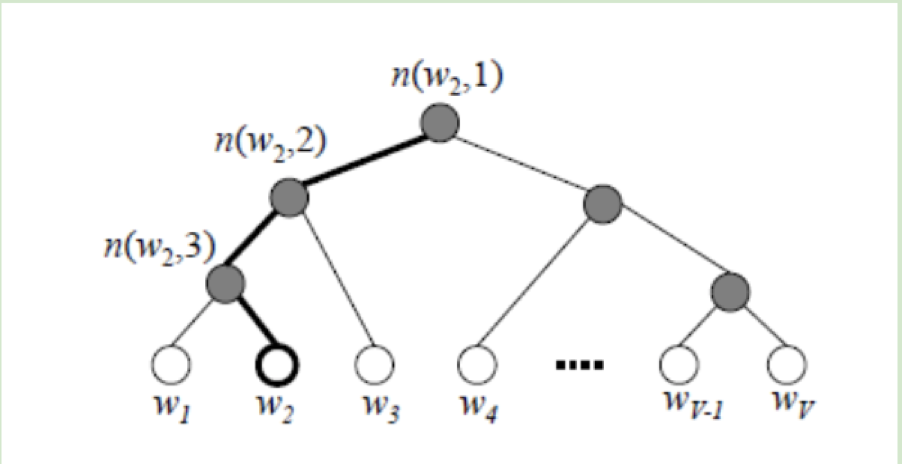
以下图为例

最底层的节点为值最小的3和4,两者构建成节点7,同时5和6构建成节点11,以此反复。
3.1.2.2 层次softmax介绍
改进
-
输入层-隐藏层:对于输入层到隐藏层的映射,将原有的线性变换+激活函数修改为输入词向量求平均。
-
隐藏层-softmax层:原神经网络模型中,输出层需要计算全部词的softmax概率。现在使用哈夫曼树的内部节点替换原神经网络的神经元。根节点的词向量对应投影后词向量。叶子节点的类似原神经网络softmax输出层的各个神经元。叶子节点个的个数就是词汇表的大小。每个叶子节点的权重为对应单词的词频。
优点
-
计算量由之前的V降低为logV。
-
哈夫曼树的构建是基于词频,高频词更接近树根,更易被找到,符合贪心优化思想。
3.1.2.3 梯度计算
编码确定
-
通过二元逻辑回归,规定沿左走为负类,沿右走位正类。以此确定从根节点到叶子节点的哈夫曼编码。
-
正类负类的判断方法是使用sigmoid函数
-
表示当前节点的词向量。θ表示当前节点的模型参数。
-
在内部节点中,下一步是沿左子树还是右子树根据P(+)P(-)概率大小选择对应方向。
似然函数
- 对于目标输出词w,最大似然为
其中,表示从根节点到w所在的叶子节点,包含的节点总数。w在哈夫曼树种,从根节点开始,经过的第j个节点,对应的编码为,该节点对应的参数为
梯度表达式
- 基于似然函数,的梯度表达式为:
由梯度表达式迭代更新词向量和参数
3.1.3 负采样
3.1.3.1 降采样
在训练语料中,有些高频词的出现频率很高,对模型的训练并没有正面的作用。因此使用降采样(subsampling)的方法,先对训练语料进行优化。
对于训练样本,遇到的每一个词,都有可能被丢弃掉。被丢弃的概率与这个词的词频有关。
其中,$$z(w_i)$$表示单词的出现频率,频率越高的词,被丢弃的概率越高。频率为1的词,只有3.3%的概率保留。
3.1.3.2 负采样过程
-
目的:每次采样时高频词更容易被采样出来,低频词不容易被采样出来。
-
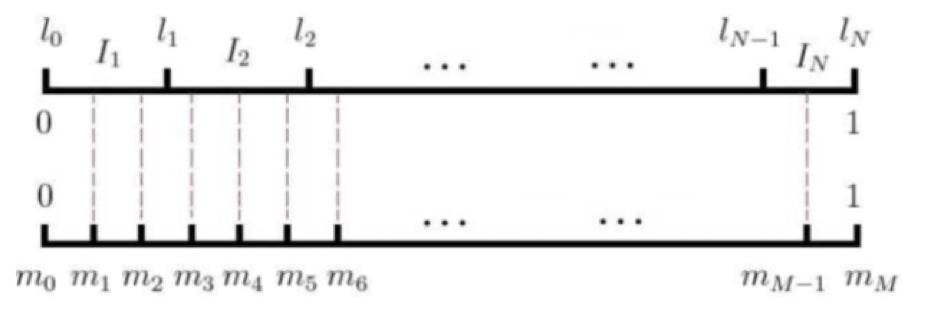
步骤1:将长度为1的线段,根据词表大小,划分成V份,每份的长度与对应词的词频有关。高频词线段长,低频词线段短。len(w)=〖count(w)〗(3/4)/(∑_(u∈V)▒〖count(u)〗(3/4) )

-
步骤2:将长度为1的线段划分成M等份,M≫V,保证M中每一份均可以对应步骤1中划分的线段。
-
步骤3:在0~M中随机生成数字,数字对应的词就是对应采样的结果。M常见设定值10^8
3.1.3.3 负采样分析
改进
-
层次softmax缺点:对于生僻词,到达叶子结点的所需的深度很深。效率相对较低。
-
负采样思路:对于一个训练样本,中心词是w,上下文为context(w)。中心词与上下文构成真实的正例。通过负采样,采集到neg个与w不同的词w_i**,i=1,2,..neg。context(w)与w_i 组成了neg个负例**。通过1个真实的正例和负采样得到的neg个负例,计算更新中心词和采样得到的neg个词对应的模型参数和词向量。
优点
- 相较原始神经网络模型,最后一层的参数计算量从 hidden_size * |V| 减少到 hidden_size * (1+neg)。 计算量相较之前有了很大的降低。
- 通过负采样算法,虽然模型的参数维度没有发生变化,但是在更新过程中的计算量进行了减少。
3.1.3.4 梯度计算
正例负例定义
-
负采样通过二元逻辑回归求解模型参数。$$w_0$$,$$w_i,i=1,2,...neg$$分表表示正例和负例
-
对于正例
-
对于负例
-
期望最大化
\prod_{i=1}^{neg}\sigma(x_{w_0}^{T}\theta^{w_i})^{y_i}(1-\sigma(x_{w_0}^{T}\theta^{w_i}))^{1-y_i}, y_i =\left\{ \begin{array}{**lr**} 1,i=0, & \\ 0,i=1,2,..,neg &\end{array} \right.
梯度表达式
- 基于似然函数,$$x_{w_0}$$的梯度表达式为
由梯度表达式迭代更新词向量$x_{w_0}$和参数$\theta^{w_i}$
Glove: Global Vectors for Word Representation。是一种基于全局词频统计的词表征工具。
3.2.1 构建步骤
-
构建共现矩阵X。矩阵中的元素X_ij表示单词i和单词j在窗口中共同出现的次数。同时根据两个单词的距离,使用1/d作为衰减函数计算权重。距离越远的两个单词,计数权重越小。
-
构建词向量与共现矩阵的近似关系。论文作者提出一个近似表达两者关系的公式, w为对应词向量,b为偏差
-
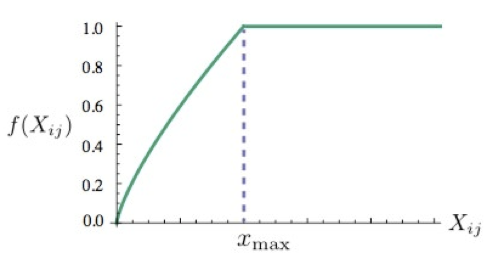
构建损失函数。基于MSE损失函数,添加权重函数$$f(x_{ij})$$。权重函数具有三个功能,
- 1)经常一起出现的单词,具有较大的权重。
- 2)权重不会随出现次数无限增加。
- 3)两个单词没有一起出现过,则权重为0
函数图像如图所示
-
损失函数如下
J=\sum_{i,j=1}^{V}f(x_{ij})(w_{i}^{T}\tilde{w_{j}}+b_i +\tilde{b_j}-log(x_{ij})^2, f(x)=\left\{ \begin{array}{**lr**} (\frac{x}{x_{max}})^2, & \\ 1 & \end{array} \right.
3.2.2 优缺点
-
优点:相较word2vec只关注局部信息,glove构建过程中参考了全局信息。在论文中理论效果优于word2vec。
-
缺点1: 因为使用了全局信息,在计算过程中内存占用过高。
-
缺点2: 因为偏差的存在,如果偏差过大,会导致各词向量比较接近,区分度低。
-
缺点3: 在实际使用中,停用词对应的向量模长通常较大,对于文本分类等任务影响较大。
4 后续发展
前面章节介绍的词向量方法,虽然相较之前有了提升,但是对于多义词的区分,已经更深更准确的词向量挖掘还存在不足。
4.1 EMLO
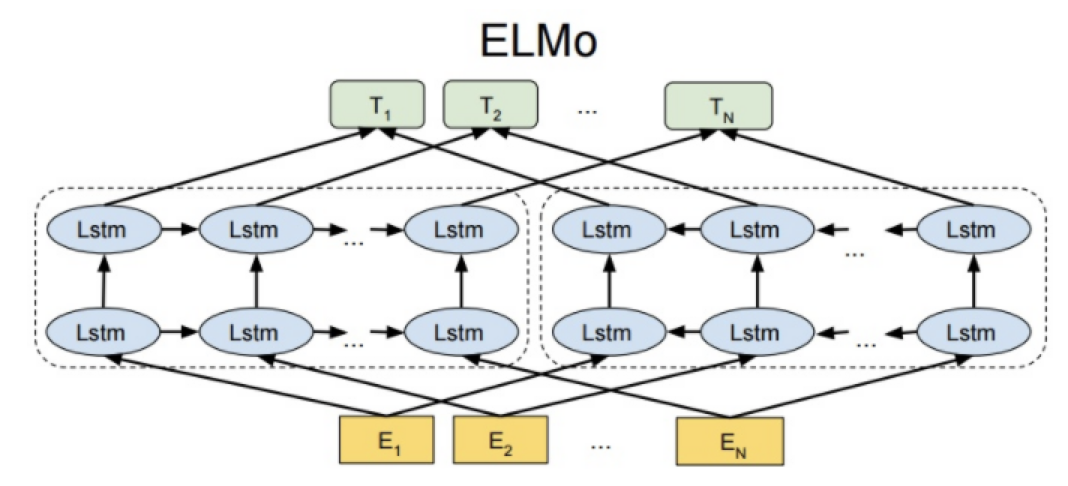
基本信息
-
基本结构:双层双向的LSTM网络结构,动态输出词向量
-
优点:针对静态词向量,可以解决多义词问题
-
缺点:特征抽取器没有使用热门的transformer
4.2 GPT
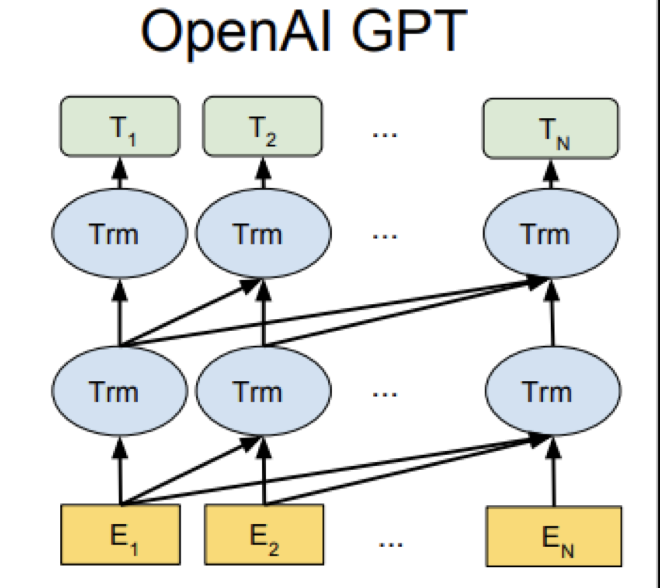
基本信息
-
基本结构:单向的transformer网络结构
-
优点:在NLP任务中效果显著,12个任务中9个达到最佳效果
-
缺点:模型为单向模型,没有结合下文信息
-
更新:2020年5月发布GPT-3,参数量高达1750亿,单次训练成本1200万美元
4.3 Bert
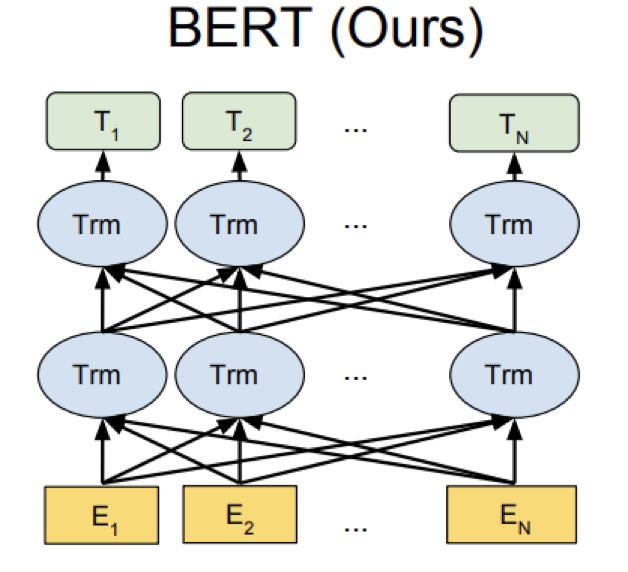
基本信息
-
基本结构:双向的transformer网络结构
-
优点:实际效果优秀,在11个NLP任务中达到最优效果
-
缺点:基于训练任务,更适合自然语言理解类任务(NLU),不适合自语言生成类任务(NLG)
5 参考文献
- NPLM: A Neural Probabilistic Language Model, 2003
- Word2vec: Efficient Estimation of Word Representation, 2013
- Distributed Representations of Words and Phrases and their Compositionality, 2013
- Glove: Glove: Global Vectors for Word Representation, 2014
- ELMo: Deep contextualized word representations, 2018
- GPT-1: Improving Language Understanding by Generative Pre-training, 2018
- GPT-2: Language Models are unsupervised multitask learners, 2019
- GPT-3: Langugae Models are few shot learners, 2020
- Bert:BERT: Pre-trainin of Deep Bidirectional Transformers for Language Understanding, 2018