Focal-loss论文解读

针对正负不均衡样本的损失函数
论文链接:Focal Loss for Dense Object Detection
1 论文目标
当前目标检测算法,主要分成两类
one-stage
- end2end,一步到位
- 速度快
- 准确度较低
- YOLO
two-stage
- 先检测,再识别
- 速度慢
- 精度较高
- Faster RCNN
目标:
通过focal loss ,使得one-stage的精度达到two-stage,同时不影响速度。
2 当前问题
one-stage准确率不如two-stage的原因是:样本的类别不均衡。
会导致的后果:
(1)training is inefficient as most locations are easy nega- tives that contribute no useful learning signal;
(2)en masse, the easy negatives can overwhelm training and lead to de- generate models. A
- 大量样本是容易分类的负样本,没有有用的贡献
- 容易分类的负样本会导致模型退化
训练数据中存在大量的容易分类的负样本,导致模型的优化效果有问题。
改进思路:
通过减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。
3 细节介绍
交叉熵:
简化为:
focal loss:
- :类别平衡参数,用来给不同类别的样本加权重。样本越不均衡,其值应该越靠近0或1。如果y=1的数量多,则参数的值应该小于0.5。
- :focusing parameter,聚焦参数,。调整难分类样本的权重,越大,预测结果越趋近0~1的两端。
- $\left (1-p_{\mathrm{t}}\right)^{\gamma} $: modulating factor,调节因子,使模型关注难分类的样本
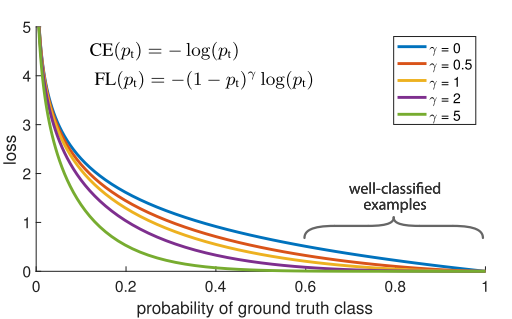
focal loss具有两个性质:
(1)When an example is misclassified and pt is small, the modulating factor is near 1 and the loss is unaffected. As pt → 1, the factor goes to 0 and the loss for well-classified examples is down-weighted.
(2) The focusing parameter γ smoothly adjusts the rate at which easy examples are down- weighted. When γ = 0, FL is equivalent to CE, and as γ is increased the effect of the modulating factor is likewise in- creased (we
- (1)当一个例子被分错后,pt很小。调节因子系数接近1,所以loss不受影响;当pt接近1时,调节因子接近于0,容易分类的例子降低了权重。
- (2)聚焦参数可以平滑的调整易分类例子权重下降的速度。当其=0时,公式等同于交叉熵。当其增加时,调节因子的效果也在增加。
4 论文总结
- 问题:模型准确率较低
- 原因:数据不均衡,大量易分类的负样本影响模型
- 方法:给交叉熵加一个调节因子,更关注难分类的样本
- 效果:理论上优于之前
6 LGB实战
参考代码: LightGBM with Focal Loss
lgb使用自定义focal-loss主要包括两个内容:
-
自定义损失函数
def focal_loss_lgb(y_pred, dtrain, alpha, gamma): """ Focal Loss for lightgbm Parameters: ----------- y_pred: numpy.ndarray array with the predictions dtrain: lightgbm.Dataset alpha, gamma: float See original paper https://arxiv.org/pdf/1708.02002.pdf """ a,g = alpha, gamma y_true = dtrain.label def fl(x,t): p = 1/(1+np.exp(-x)) return -( a*t + (1-a)*(1-t) ) * (( 1 - ( t*p + (1-t)*(1-p)) )**g) * ( t*np.log(p)+(1-t)*np.log(1-p) ) partial_fl = lambda x: fl(x, y_true) grad = derivative(partial_fl, y_pred, n=1, dx=1e-6) hess = derivative(partial_fl, y_pred, n=2, dx=1e-6) return grad, hess -
自定义评估函数
def focal_loss_lgb_eval_error(y_pred, dtrain, alpha, gamma): """ Adapation of the Focal Loss for lightgbm to be used as evaluation loss Parameters: ----------- y_pred: numpy.ndarray array with the predictions dtrain: lightgbm.Dataset alpha, gamma: float See original paper https://arxiv.org/pdf/1708.02002.pdf """ a,g = alpha, gamma y_true = dtrain.label p = 1/(1+np.exp(-y_pred)) loss = -( a*y_true + (1-a)*(1-y_true) ) * (( 1 - ( y_true*p + (1-y_true)*(1-p)) )**g) * ( y_true*np.log(p)+(1-y_true)*np.log(1-p) ) return 'focal_loss', np.mean(loss), False在实际使用中,通过
fobj和feval指定对应的自定义损失函数和评估函数。示例如下:focal_loss = lambda x,y: focal_loss_lgb(x, y, 0.25, 2., 10) eval_error = lambda x,y: focal_loss_lgb_eval_error(x, y, 0.25, 2., 10) params = {'learning_rate':0.1, 'num_boost_round':10, 'num_class':10} model = lgb.train(params, lgbtrain, valid_sets=[lgbeval], fobj=focal_loss, feval=eval_error)Sklearn API
如果使用Sklearn API,需要用
y_rtue替换原函数中的dtrain,并交换预测值和实际值的顺序。def focal_loss_lgb_sk(y_true, y_pred, alpha, gamma): """ Focal Loss for lightgbm Parameters: ----------- y_pred: numpy.ndarray array with the predictions dtrain: lightgbm.Dataset alpha, gamma: float See original paper https://arxiv.org/pdf/1708.02002.pdf """ a,g = alpha, gamma def fl(x,t): p = 1/(1+np.exp(-x)) return -( a*t + (1-a)*(1-t) ) * (( 1 - ( t*p + (1-t)*(1-p)) )**g) * ( t*np.log(p)+(1-t)*np.log(1-p) ) partial_fl = lambda x: fl(x, y_true) grad = derivative(partial_fl, y_pred, n=1, dx=1e-6) hess = derivative(partial_fl, y_pred, n=2, dx=1e-6) return grad, hess def focal_loss_lgb_eval_error_sk(y_true, y_pred, alpha, gamma): """ Adapation of the Focal Loss for lightgbm to be used as evaluation loss Parameters: ----------- y_pred: numpy.ndarray array with the predictions dtrain: lightgbm.Dataset alpha, gamma: float See original paper https://arxiv.org/pdf/1708.02002.pdf """ a,g = alpha, gamma p = 1/(1+np.exp(-y_pred)) loss = -( a*y_true + (1-a)*(1-y_true) ) * (( 1 - ( y_true*p + (1-y_true)*(1-p)) )**g) * ( y_true*np.log(p)+(1-y_true)*np.log(1-p) ) return 'focal_loss', np.mean(loss), False实际使用用例如下:
focal_loss = lambda x,y: focal_loss_lgb_sk(x, y, 0.25, 2.) eval_error = lambda x,y: focal_loss_lgb_eval_error_sk(x, y, 0.25, 2.) model = lgb.LGBMClassifier(objective=focal_loss, learning_rate=0.1, num_boost_round=10) model.fit( X_tr, y_tr, eval_set=[(X_val, y_val)], eval_metric=eval_error)
参数探索
-
探索内容:
focal-loss中有主要有2个参数可以调节,分别为:
alpha:
类别平衡参数,用来给不同类别的样本加权重。样本越不均衡,其值应该越靠近0或1。如果y=1的数量多,则参数的值应该小于0.5。
gamma:
调整难分类样本的权重,其值越大,预测结果越趋近0~1的两端。
分别固定一个参数,探索另一个参数对模型的效果。
-
测试数据正负比例约为1:9
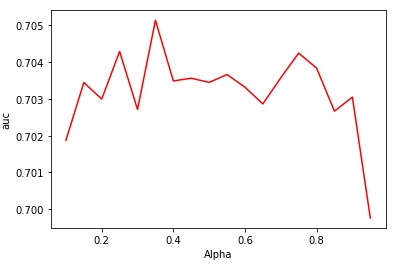
3.3.1 Alpha
固定gamma=2.0,探索 alpha从0.1~1.0的效果
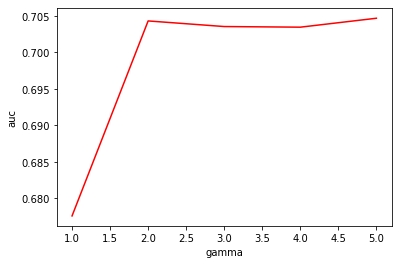
3.3.2 Gamma
固定alpha=0.25,探索gamma从1.0~5.0的效果
-
结论:
1.alpha在0.25~0.75效果比较接近,其中0.35效果最佳
2.提高gamma可以略微提高模型效果,其中gamma=5.0效果最佳
3.选择效果最佳的alpha和效果最佳的gamma组合,效果反而下降。
4.不同的正负样本比例对应的最佳参数应该不同,需要根据实际情况确定