Bert总结

Bert的论文解读和基于pytorch的基本用法
1 介绍
bert全称:Bidirectional Encoder Representation from Transformers,双向Transformer的Encoder。
简单概况,bert就是一个多层transformer的encoder叠加的文本特征抽取模型。
在实际的任务上取得了很好的效果。同时操作简单。 发布后被广泛使用。
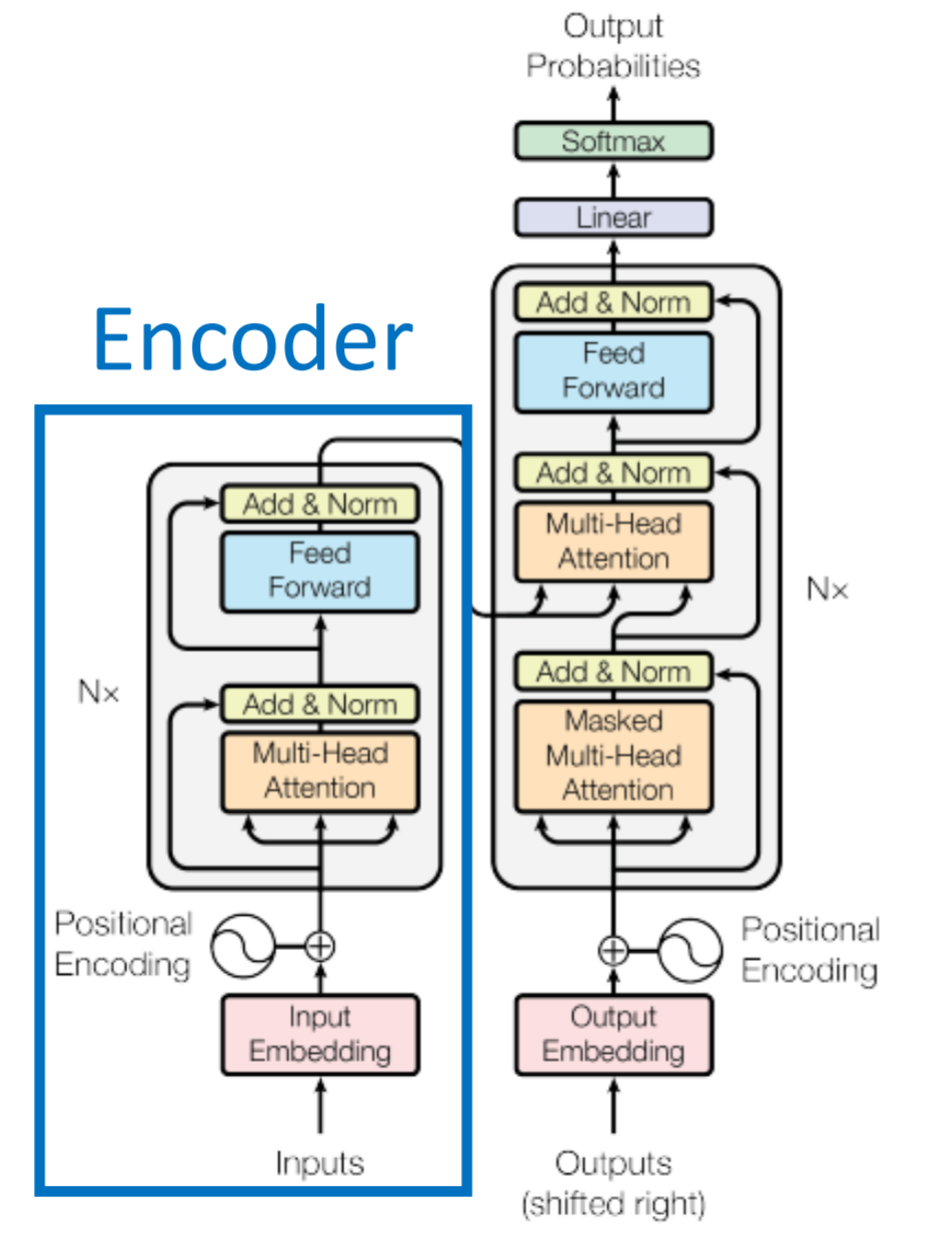
bert的主要的作用就是将输入的文本进行编码,抽取特征,将输入的文本转成向量,可以看出word2vec的高级版。
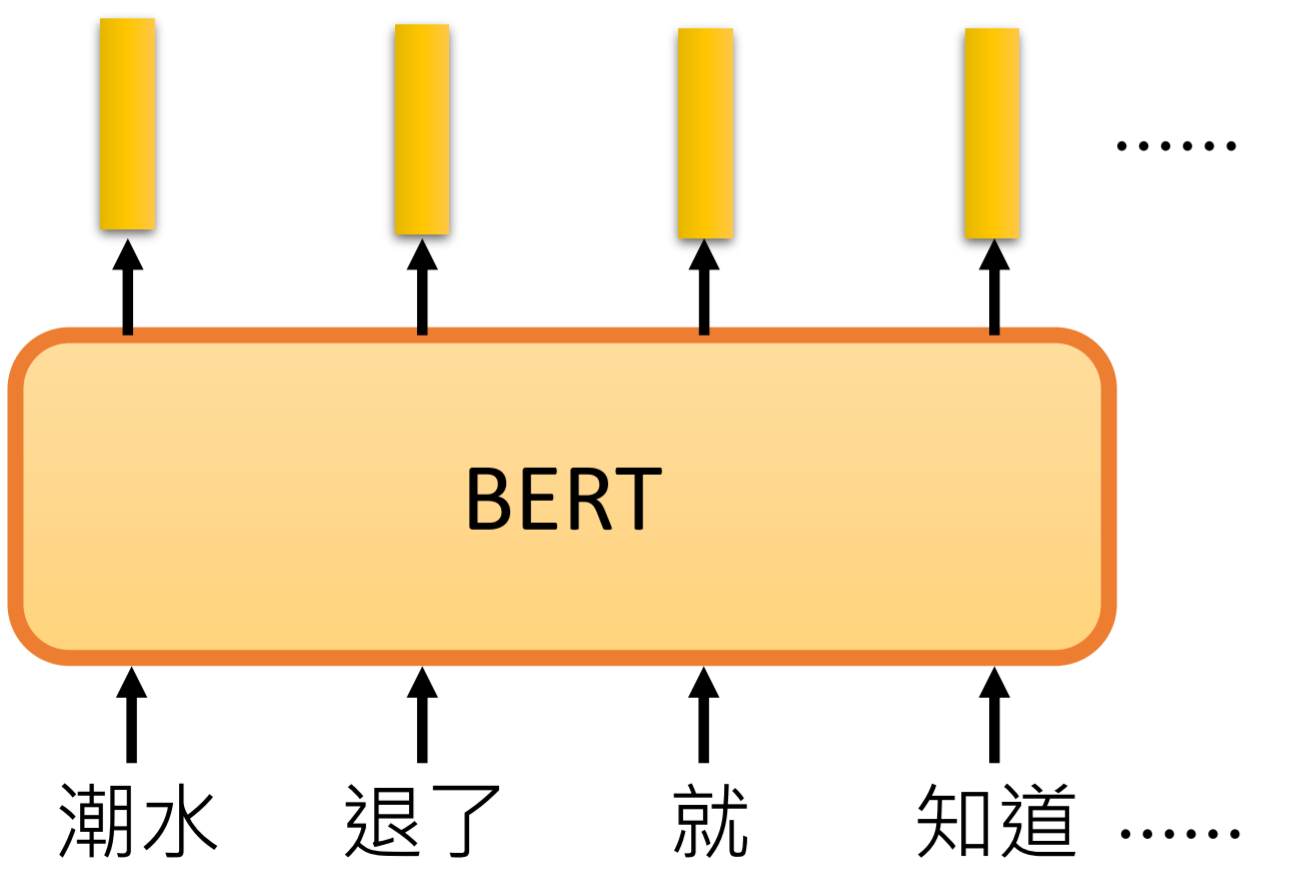
2 模型
2.1 基本结构
bert模型模型结构为: 输入->多层transformer的encoder->输出
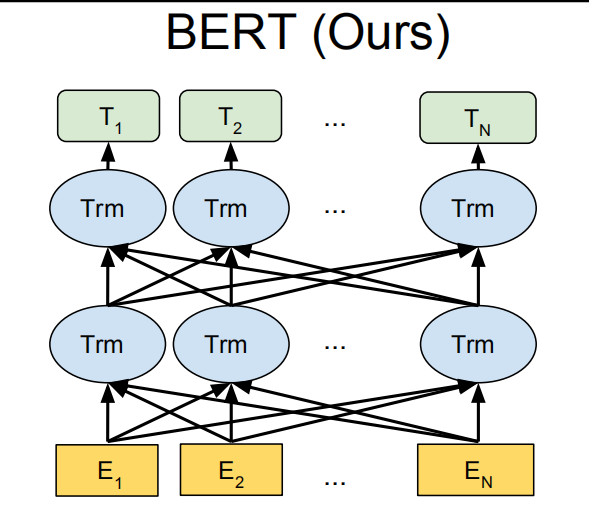
模型大致分成base版本和large版本。
Base版本: 12层transformer encoder,隐藏层神经元768,self-attention head数量12,110M个参数。
Large版本:24层transformer encoder,隐藏层神经元1024,self-attention head数量16,340M个参数。
输入表示
表示输入的embedding,一共由3部分组成:
token_embedding + segment_embeddin +position_embedding
token_embedding: 词向量
输入文本在进入token embedding之前,会加入cls和sep两个特殊标记符。
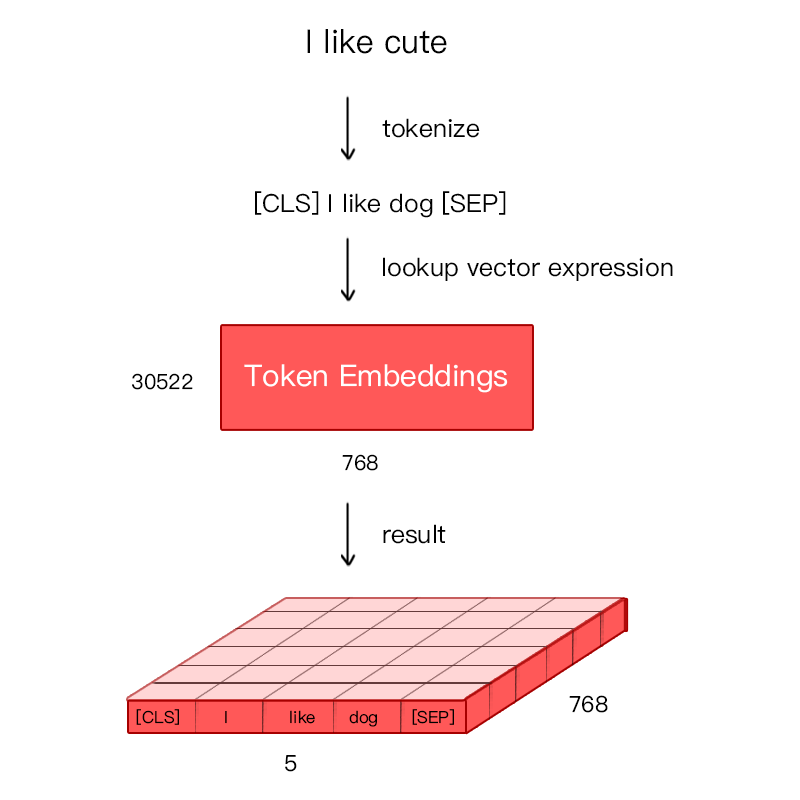
为了避免未登录词问题,bert中使用了Word Piece处理方法。对于英文单词进行了更细粒度的切分。
如playing会被切成play 和 #ing 两个更细粒度的词。 此方法不适用于中文,中文bert在使用中会以单个汉字为最小单元。
segment_embedding: 句向量
用来区分两个句子是否是一个句子。前一个句子用0表示,后一个句子用1表示。
如果输入只有一个句子,则segment embedding就全部是0。
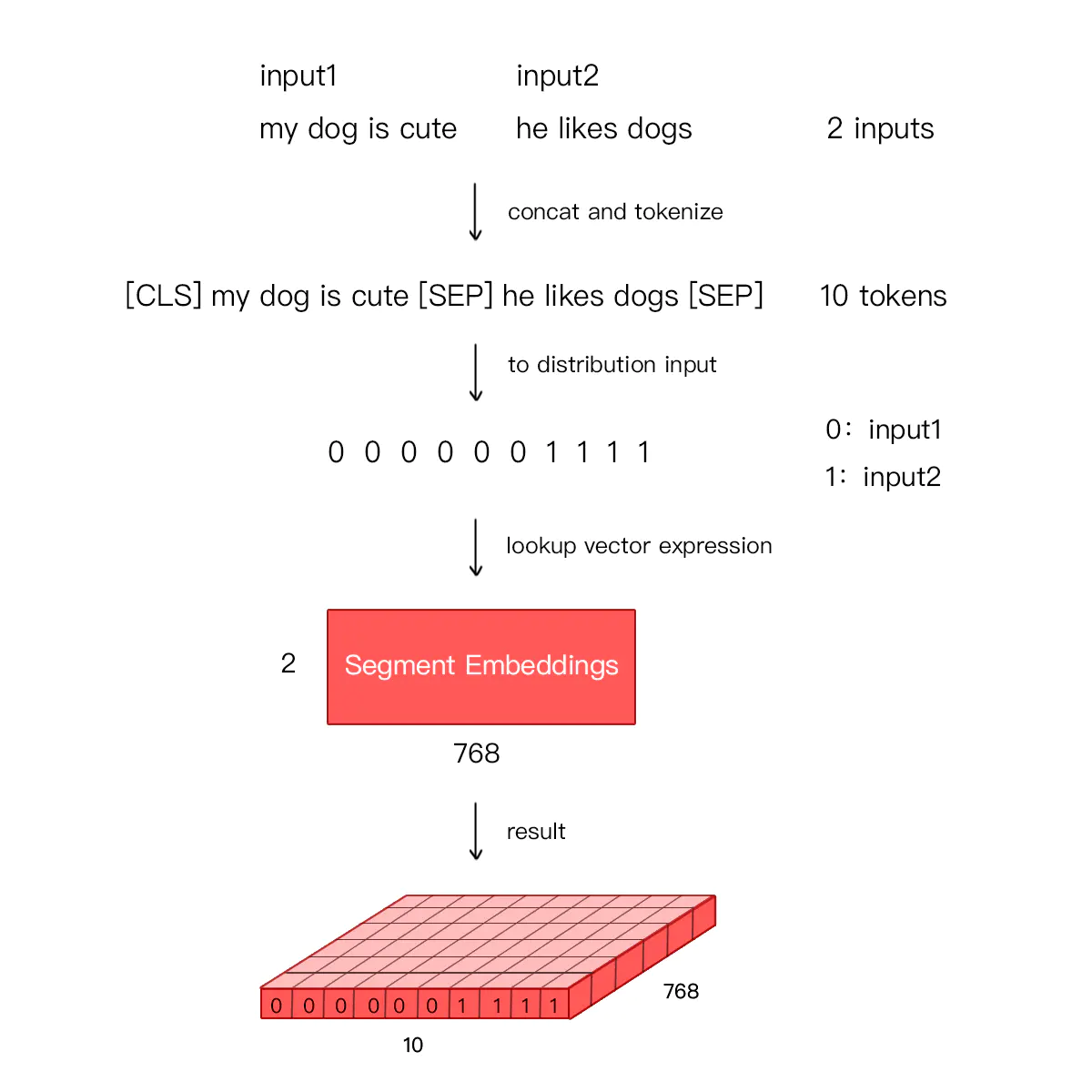
position_embedding: 位置向量
transformers使用三角函数编码,对偶数位置使用正弦编码,奇数位置使用余弦编码。
Bert的postition embedding改为可以学习的向量,在训练过程中学习位置信息。
注意:bert的输入最大长度为512(包括cls和sep)。超过的会被截断。
2.2 各层作用
bert的24层按从底层到高层,学习到的信息逐渐抽象。层数越高,学习到的信息越高级。
具体每一层具体学习到什么内容可以参考论文:BERT Rediscovers the Classical NLP Pipeline。该论文尝试解释了bert每一层在学习什么信息。
论文使用8种NLP任务,对bert各层的作用进行了测试。
8种测试任务:句法分析(POS),成分分析(Consts),依存分析(Deps),实体识别(Entities),语义角色标注(SRL),共指消解(Coref),语义原始角色标注(SPR),关系分类(SemEval)。
下图中每一行图片表示一种nlp任务,每一行的图片,蓝色的宽度表示该层的向量对任务的重要程度。横轴表示对应的bert层数,越向右,层数约大。
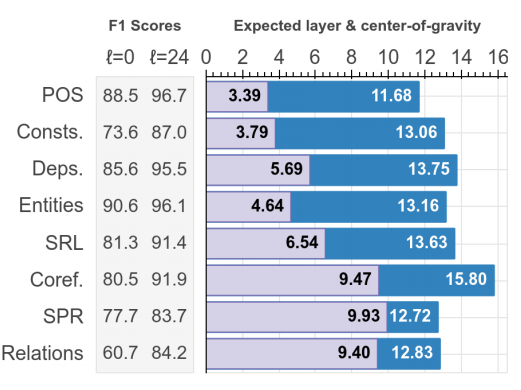
下图中右侧数值,expected layer的值(粉色部分)表示对应任务在哪一层被较好的解决。center-of-gravity的值(蓝色)越高,代表对应任务需要更高层的编码信息。
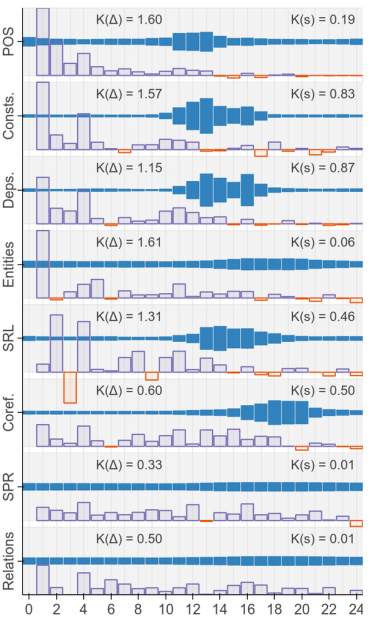
从图中可以得出结论,对于较关注词本身性质的任务,底层的结果比较重要。越复杂的任务,高层输出的结果越重要。语法信息出现在bert的较低层,高级的语义信息出现在较高层。
3 模型训练
训练语料
英文使用:BooksCorpus (800M words), English Wikipedia(2500M words)
中文使用:主要基于中文维基百科的全部内容
训练用时
base版本:4 Cloud TPU, 4天
large版本: 16 Cloud TPU,4天
实际使用中,默认加载预训练好的模型进行微调(fine-tune)。不会重新训练一个bert模型。
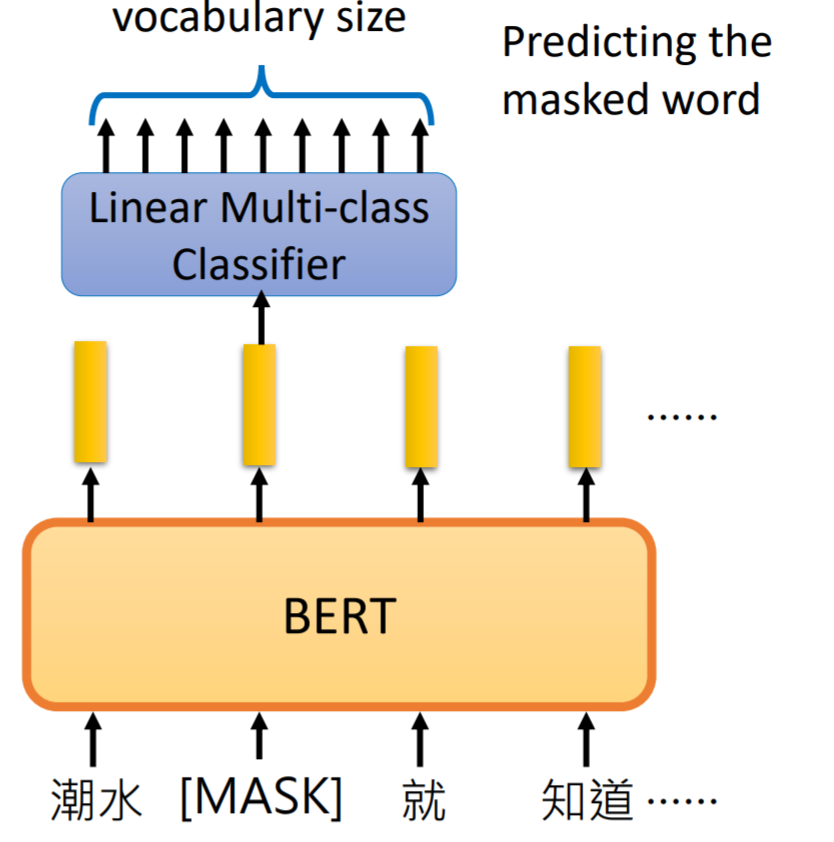
训练任务1:Masked LM
在训练语料中,随机将15%的token替换成[mask]字符,去根据前后信息预测mask的词。
[mask]在实际任务中不会出现,导致训练语料与实际语料存在偏差。为了降低影响,对需要mask的词进行3种替换方式
-
80%的token使用mask替换
-
10%随机取其他的token替换当前的词
-
10%保持不变
预测位置对应的token的输出向量接一个线性分类。
选用线性分类器的原因: 分类能力弱,如果希望模型的分类准确,需要bert层抽取特征效果足够好。
训练任务2:Next Sentence Prediction(NSP)
输入一个句子对,预测第二句是否是第一句的下文。
输入两个句子,句子A和句子B,其中句子B有50%的概率为句子的下一句。
训练中用的两个标志符:
[CLS] : 句子类别信息,出现在第一句的首位。
[SEP] : 句子分隔符,出现在句子的结尾处。
4 具体使用
使用预训练+微调的方式进行实际任务操作。
基于预训练好的bert模型,针对不同的任务后接不同的输出层。
新增的输出层和预训练的模型参数同时训练。
论文中给出了4种常见任务类型的使用方法
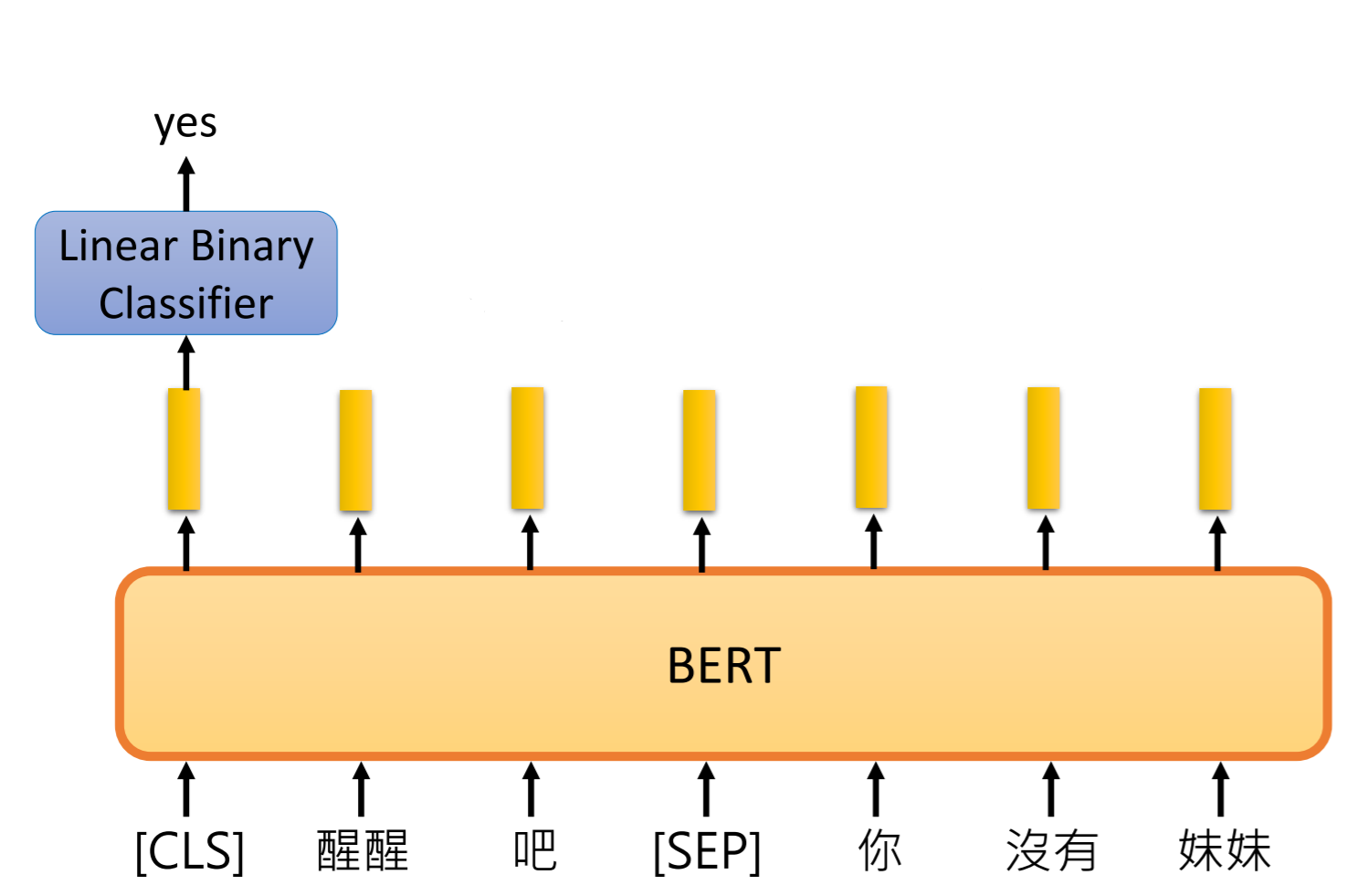
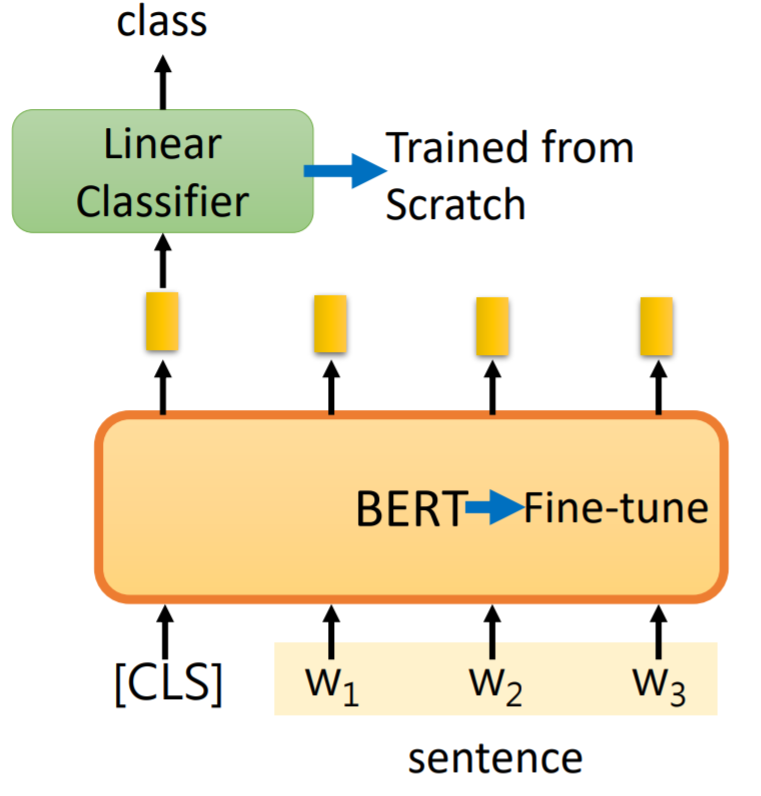
case1
输入:单个句子
输出:类别
常见任务: 文本分类
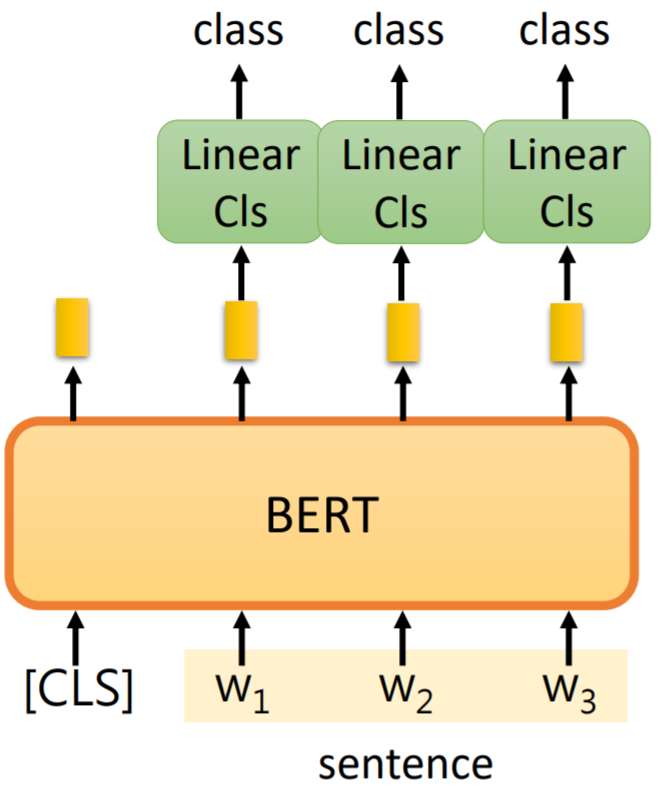
case2
输入:单个句子
输出:每个token的分类
常见任务:命名实体识别
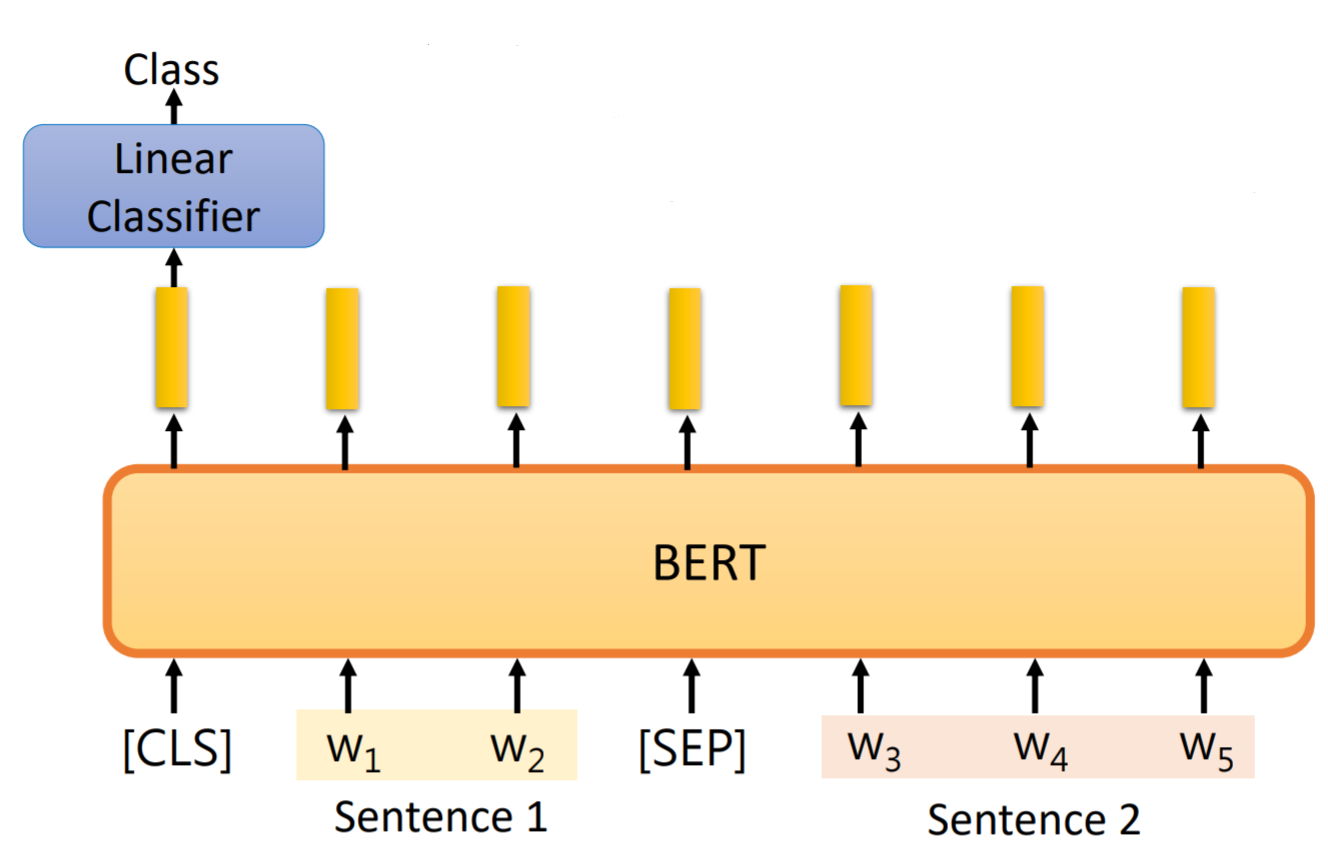
case3
输入:2个句子
输出:分类结果
常见任务:推断任务
case4
QA类任务。
任务介绍:
输入为 文本(document)和问题(query),通过模型,输出答案的起始位置。对应区间则为问题的答案。
假设:如果问题可回答,答案一定可以从文本中抽取,无需生成答案。
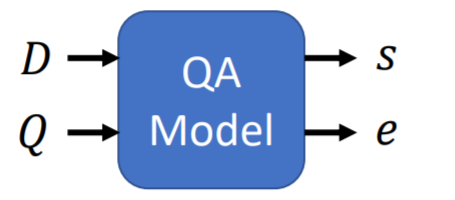
bert-QA任务
引入两个可以学习的向量分别代表答案的起点和终点位置。
squad 1.1(问题皆可回答)
S(start)和E(end)分别
与document经过bert的输出向量做点乘,结果中概率最大的值为对应的索引的位置。
实际计算中,会计算起点终点加和最高作为答案区间。
S和E各自的损失函数加和,作为训练过程中的损失函数。
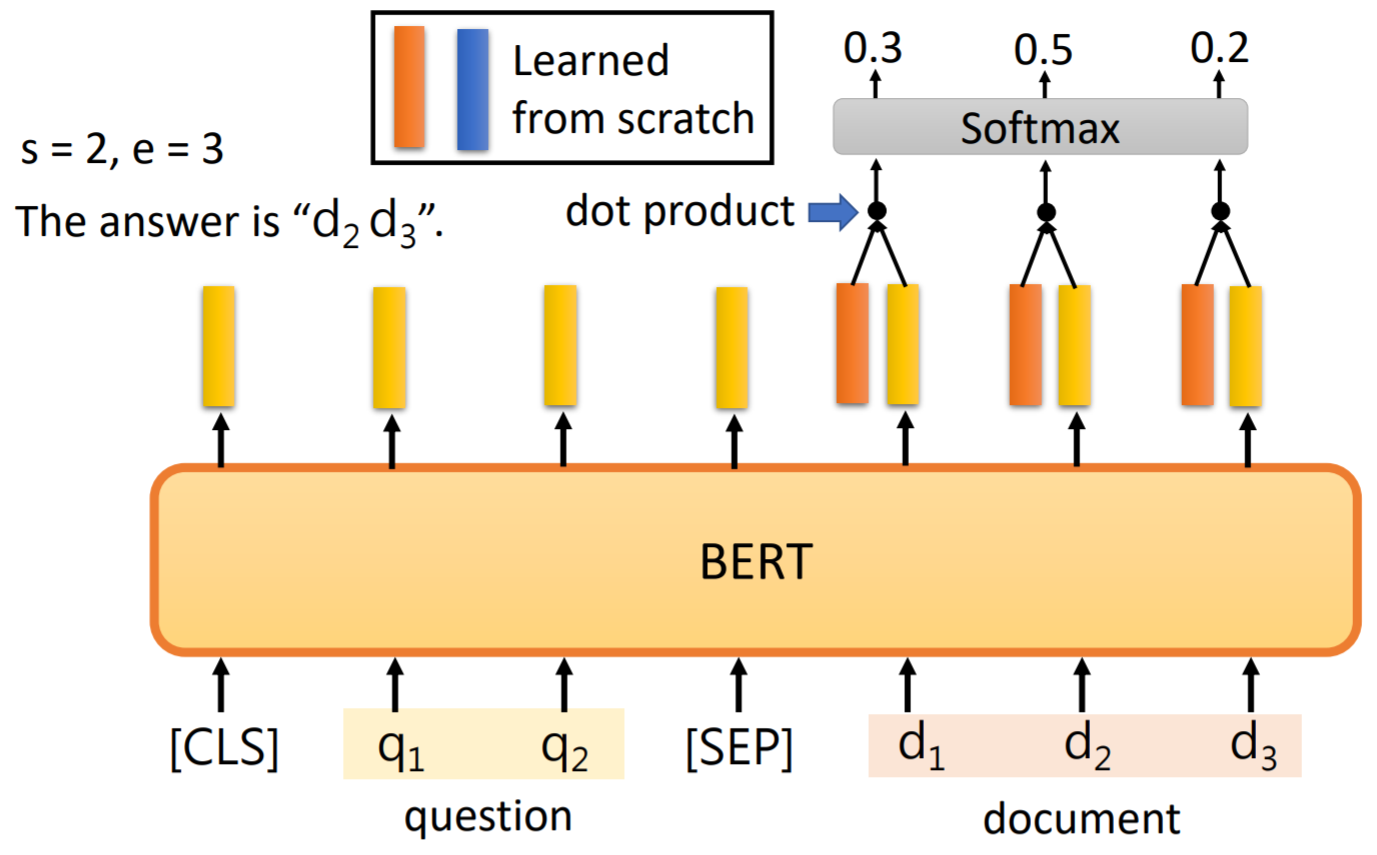
squad 2.0(部分问题无答案)
-
不可回答问题: 起点和终点索引均指向cls。起点大于终点也可被看作无答案。
-
答案计算过程:
最佳可回答答案得分:
不可回答得分:
答案非空标准:
其他类型
-
bert可以看成word2vec的升级版,因此可以使用bert替换原有任务中的word2vec,对输入的文本进行向量化。如文本分类,将第一步的向量化使用bert。命名实体任务:把word2vec+bilstm+crf修改为bert+bilstm+crf。
-
分类任务除了可以使用cls的输出结果,也可以将各个token的向量作为后续计算的向量。接入不同的分类器。
-
文本抽取类可以参考case4,将两个输入改为只输入一个句子,计算起点和终点的位置。也可以参考case2,对每一个token做分类,判断是否属于抽取内容。也可基于bert抽取的结果,做更复杂的操作。
5 代码应用
TensorFlow版本:谷歌官方 https://github.com/google-research/bert
pytorch版本(推荐): transformers第三方库
pip install transformers
import torch
from transformers import BertModel, BertTokenizer
# 可以通过名字直接加载模型 或 事先下载模型此处为模型路径
model_name = 'bert-base-uncased'
# 读取模型对应的tokenizer
tokenizer = BertTokenizer.from_pretrained(model_name)
# 载入模型
model = BertModel.from_pretrained(model_name)
# 输入文本
input_text = "Here is some text to encode"
# 通过tokenizer把文本变成 token_id
input_ids = tokenizer.encode(input_text, add_special_tokens=True)
# input_ids: [101, 2182, 2003, 2070, 3793, 2000, 4372, 16044, 102]
# encode会自动添加标记符
tokenizer.convert_ids_to_tokens(input_ids)
['[CLS]', 'here', 'is', 'some', 'text', 'to', 'en', '##code', '[SEP]']
input_ids = torch.tensor([input_ids])
# 获得BERT模型输出
output = model(input_ids)
last_hidden_state = output[0] # batch_size * seq_length * hidden_size
pooler_output = output[1] # batch_size * hidden_size, first token(cls)
# 冻结bert参数
# BertModel
for param in model.parameters():
param.requires_grad = False
# eg: BertForSequenceClassification
for param in model.bert.parameters():
param.requires_grad = False
更多细节用法参考:
https://huggingface.co/transformers/quicktour.html
参考文献
[1] Attention is all you needed
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding